Most datasets have a high number of dimensions along which the data is distributed. It is key to understand how to visualize high-dimensional datasets. This can be achieved using techniques known as dimensionality reduction. This post will focus on two techniques: PCA and t-SNE.
Firstly, let's get some high-dimensional data to work with.
MNIST dataset
We grab the MNIST dataset using Scikit Learn.
1 | import numpy as np |
Then convert the matrix and vector to a Pandas DataFrame.
1 | import pandas as pd |
To ensure randomisation, we create a random permutaion of the number 0 to 69,999.
1 | rndperm = np.random.permutation(df.shape[0]) |
Then we generate 30 plots of randomly selected images.
1 | %matplotlib inline |

These images are all essentially 28-by-28 pixel images and therefore have a total of 784 dimensions, each holding the value of one specific pixel.
Let's implement dimensional reductions on this dataset.
PCA (Principal Component Analysis)
PCA is a technique for reducing the number of dimensions in a dataset while retaining most information.
It is using the correlation between some dimensions and tries to provide a minimum number of variables that keeps the maximum amount of variation or information about how the original data is distributed.
We will use the Scikit-Learn implementation of PCA.
Since we want to plot in 2-Dimensional figure, let's start with that and generate the first two pricipal components. We will see how much of the variation in the total dataset they actually account for.
1 | from sklearn.decomposition import PCA |
We create a scatterplot of the first and second pricipal component and color each of the different types of digits with a different color.
1 | from ggplot import * |
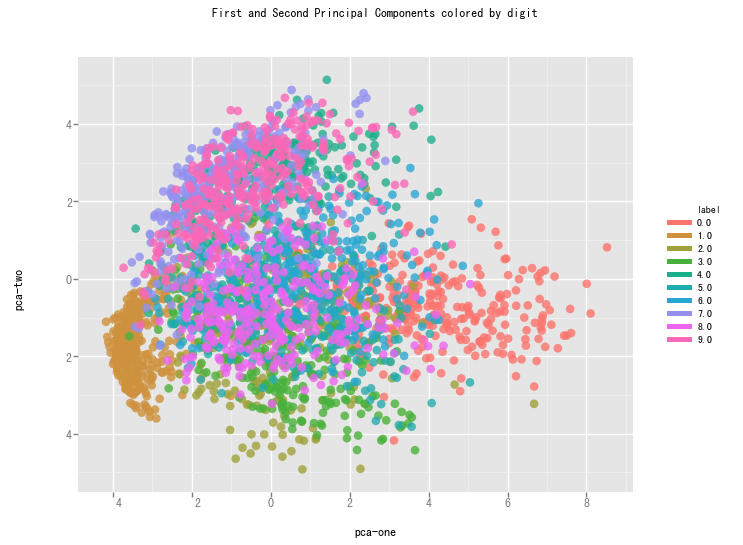
From the graph we can see that the two components definitely hold some information, but clearly not enough to set all of them apart.
t-SNE (t-Distributed Stochastic Neighbouring Entities)
t-SNE is another technique for dimension reduction and is particular well suited for the visualization of high-dimensional datasets. Contrary to PCA, it is not a mathematical technique but a probablistic one.
The original paper describes the working of t-SNE as:
t-Distributed stochastic neighbor embedding (t-SNE) minimizes the divergence between two distributions: a distribution that measures pairwise similarities of the input objects and a distribution that measures pairwise similarities of the corresponding low-dimensional points in the embedding.
It is highly recommended to use another dimensionality reduction method (e.g. PCA for dense data or TruncatedSVD for sparse data) to reduce the number of dimensions to a reasonable amount (e.g. 50) if the number of features is very high.
The other key drawback is that:
Since t-SNE scales quadratically in the number of objects N, its applicability is limited to data sets with only a few thousand input objects; beyond that, learning becomes too slow to be practical (and the memory requirements become too large).
We will use the Scikit-Learn Implementation of the algorithm in the remainder of this writeup.
Contrary to the recommendation above we will first try to run the algorithm on the actual dimensions of the data (784) and see how it does. To make sure we don’t burden our machine in terms of memory and power/time we will only use the first 7,000 samples to run the algorithm on.
1 | import time |
1 | df_tsne = df.loc[rndperm[:n_sne],:].copy() |
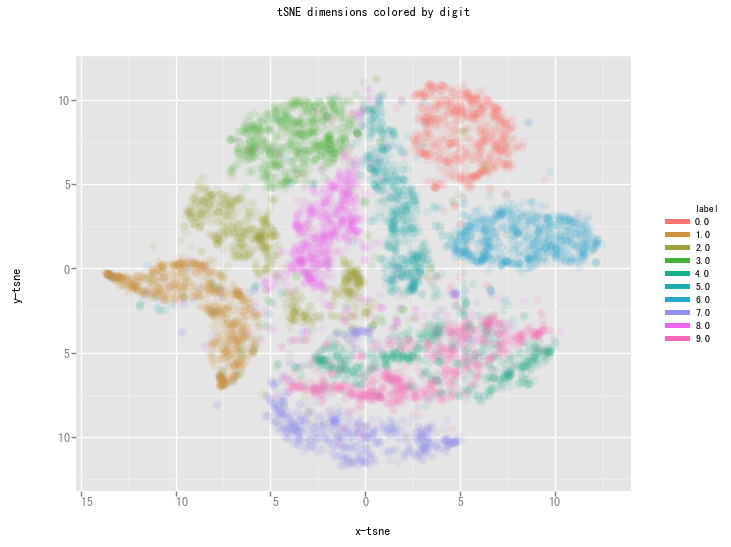
This is already a significant improvement over the PCA visualization we used earlier. We can see that the digits are very clearly clustered in their own little group.
Reference
Visualising high-dimensional datasets using PCA and t-SNE in Python