这是CVPR2018的一篇做细粒度图像分类的文章。
文章链接:https://arxiv.org/pdf/1611.09932.pdf
。
这篇文章提出的模型比较简单,通过学习一系列的1x1卷积,来增强CNN的mid-level学习能力。而且这个模型是end-to-end的,不需要额外的bounding
box等标签。
模型的出发点是:图片经过CNN后,得到了高层语义的feature
map,其中每个spatial location都对应着原始图像上的一个patch,feature
map中相应越高的地方,其对应的patch,也就是图像在分类的时候,更关注的区域,找到这些区域,对于做细粒度分类很有帮助(并且具有很强的可解释性)。
这个方法的motivation如下图所示:
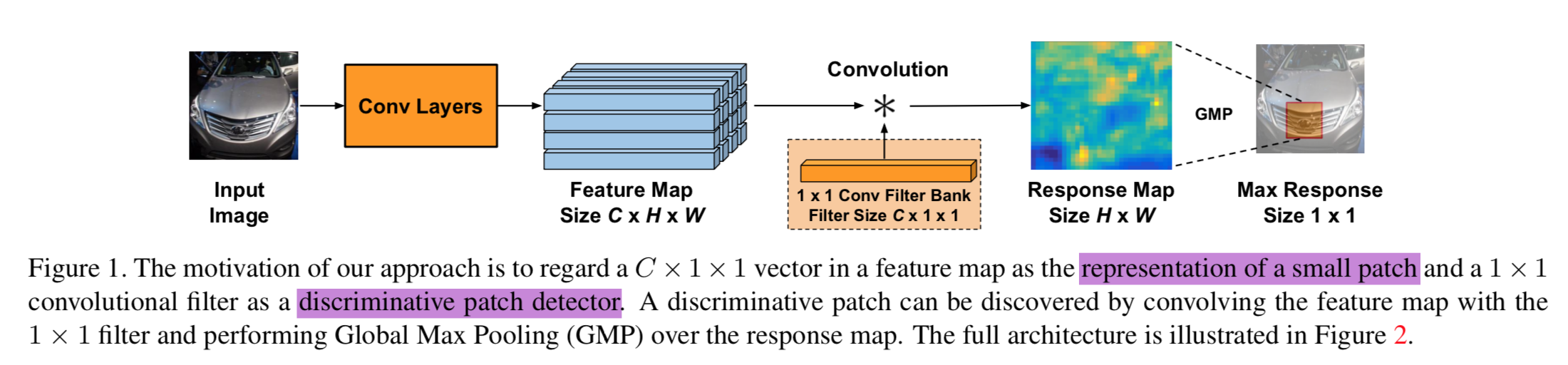
拿base
model为VGG16举例(不限于VGG16,ResNet也可以),模型的整体结构如下图所示:
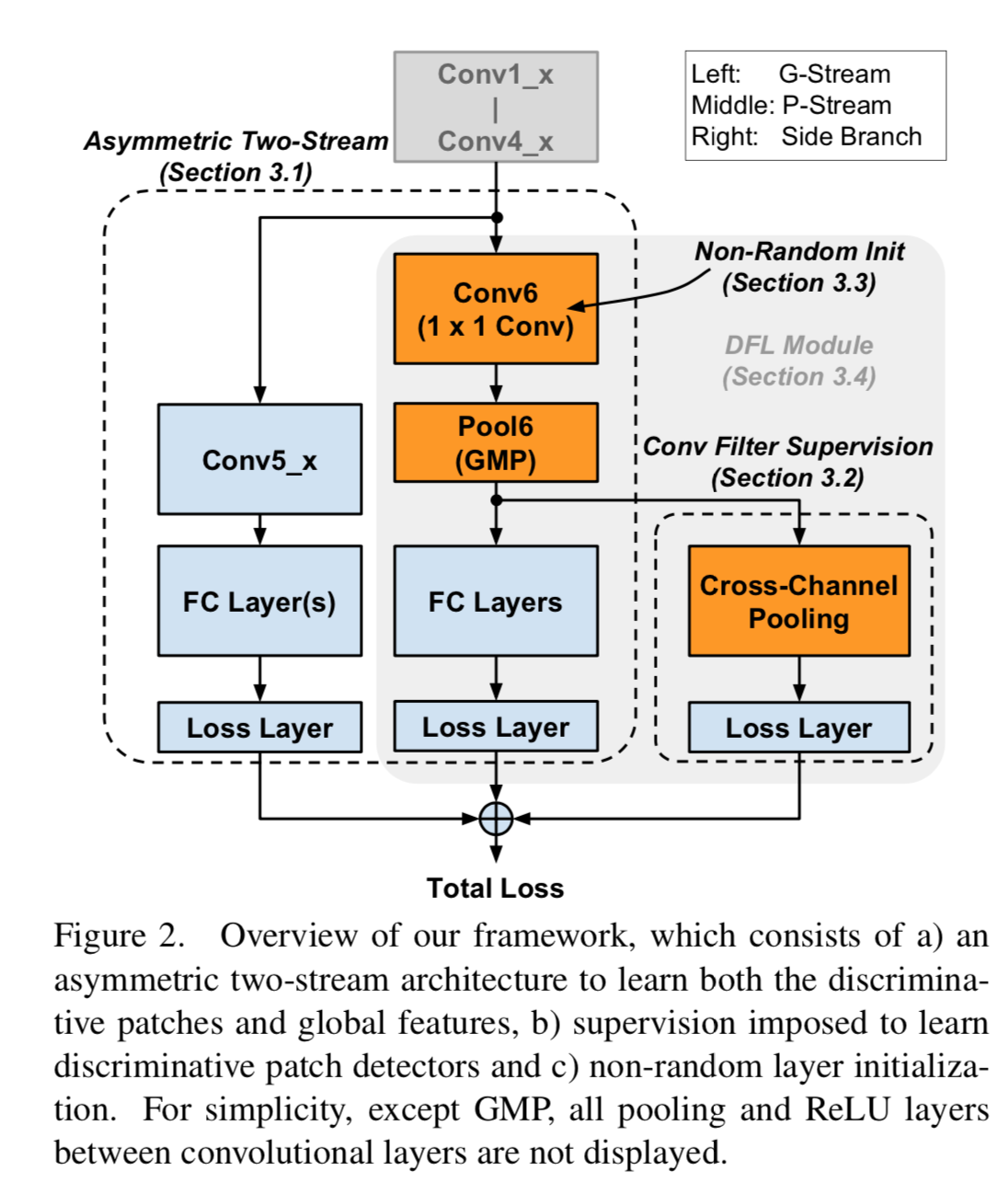
先用基础的VGG16的 Conv1 - Conv4 层,提取出feature
map,然后分为3个branch,从左到右依次命名为: G-Stream, P-Stream, Side
Branch。
G-Stream 就是基础的VGG16的Conv 5 + fc layer,用于提取global
特征,所以叫G-Stream。
P-Stream 用于提取discriminative patches,所以叫
P-Stream。VGG16的Conv4_3层的每一个spatial
location,在原始图片的receptive
field是一个92x92的patch。先用一个1x1的卷积层对feature
map做卷积,然后通过Global Maximum Pooling层,最后通过一个fc层分类。
Side branch的作用是对conv6层做supervision。核心是一个Cross-Channel
Pooling层,其实也就是一个一维pooling层,具体如下图所示:
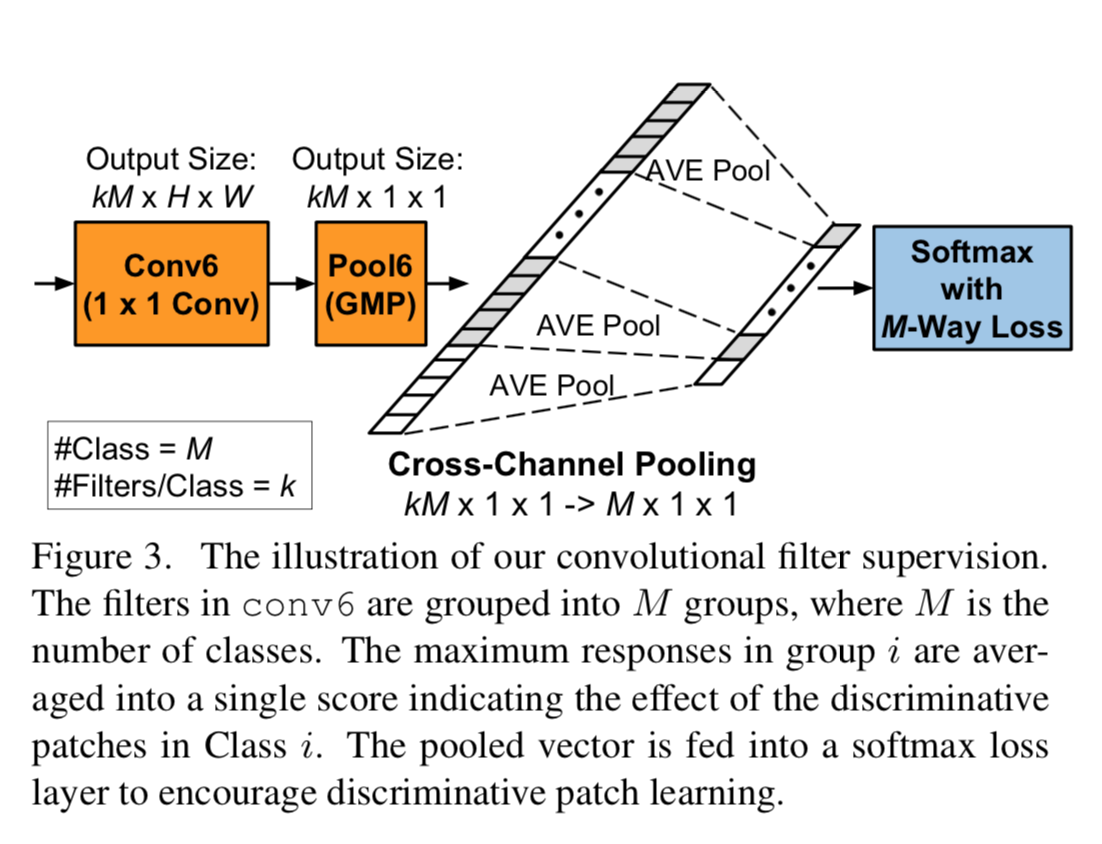
这里的supervision就是,之前1x1的卷积核有kxM个,经过 Conv 6 + Pool 6
之后,得到的是一个 kM x 1 x 1
的向量,这里我们认为每k个对应一个class,所以做一个一维average
pooling,得到Mx1x1的向量,用于最后的分类。
GitHub上有同学用PyTorch复现了这篇paper的代码(然而我并不能用他的代码得到他所说的结果...),模型部分如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| class DFL_VGG16(nn.Module):
def __init__(self, k = 10, nclass = 200):
super(DFL_VGG16, self).__init__()
self.k = k
self.nclass = nclass
vgg16featuremap = torchvision.models.vgg16_bn(pretrained=True).features
conv1_conv4 = torch.nn.Sequential(*list(vgg16featuremap.children())[:-11])
conv5 = torch.nn.Sequential(*list(vgg16featuremap.children())[-11:])
conv6 = torch.nn.Conv2d(512, k * nclass, kernel_size = 1, stride = 1, padding = 0)
pool6 = torch.nn.MaxPool2d((56, 56), stride = (56, 56), return_indices = True)
self.conv1_conv4 = conv1_conv4
self.conv5 = conv5
self.cls5 = nn.Sequential(
nn.Conv2d(512, 200, kernel_size=1, stride = 1, padding = 0),
nn.BatchNorm2d(200),
nn.ReLU(True),
nn.AdaptiveAvgPool2d((1,1)),
)
self.conv6 = conv6
self.pool6 = pool6
self.cls6 = nn.Sequential(
nn.Conv2d(k * nclass, nclass, kernel_size = 1, stride = 1, padding = 0),
nn.AdaptiveAvgPool2d((1,1)),
)
self.cross_channel_pool = nn.AvgPool1d(kernel_size = k, stride = k, padding = 0)
def forward(self, x):
batchsize = x.size(0)
inter4 = self.conv1_conv4(x)
x_g = self.conv5(inter4)
out1 = self.cls5(x_g)
out1 = out1.view(batchsize, -1)
x_p = self.conv6(inter4)
x_p, indices = self.pool6(x_p)
inter6 = x_p
out2 = self.cls6(x_p)
out2 = out2.view(batchsize, -1)
inter6 = inter6.view(batchsize, -1, self.k * self.nclass)
out3 = self.cross_channel_pool(inter6)
out3 = out3.view(batchsize, -1)
return out1, out2, out3, indices
|
Section 3.3 讲的是如何初始化Conv
6的权重,大致意思是,先找到conv4_3的feature map上energy最大的spatial
location,然后用NMS +
kmeans的方法对每个class取出topk,作为这个class对应的卷积核的初始化权重。
但是在复现的时候,并没有去做这个步骤…
一是做起来的确比较麻烦,二是感觉初始化只是会提高训练的起点,对最终训练的结果影响也不大。
最后,我把这个方法应用到了我当前的脊骨分类问题中,效果提升并不理想...
感觉医疗图像和自然图像区别还是挺大的...