这是中科院投稿 CVPR 2019 的一篇关于弱监督语义分割的文章。
Motivation
弱监督语义分割任务是只给出图片的标注,通过训练网络得到像素级的分割结果。
当前state-of-the-art的方法是通过图片的标注生成 proxy segmentation
mask,然后再以此为标签训练分割网络。作者认为,这种方式独立处理每张图片,没有考虑cross-image relationship。
于是,作者在这篇文章中提出了end-to-end affinity module来对图片间的关系建模,这样一张图片可以得到其他图片的补充信息,而且一组图片间还可以共享监督信息,来提高模型效果。
在Pascal VOC 2012数据集上,他们达到了 64.1% mIOU (val) 和 64.7% mIOU(test) 的效果。
Approach
该方法可以分为两部分:
- 生成初始的 proxy segmentation masks;
- 通过 cross-image affinity module 来训练 segmentation network。
首先,和之前的方法一样,通过CAM来生成 initial seeds。
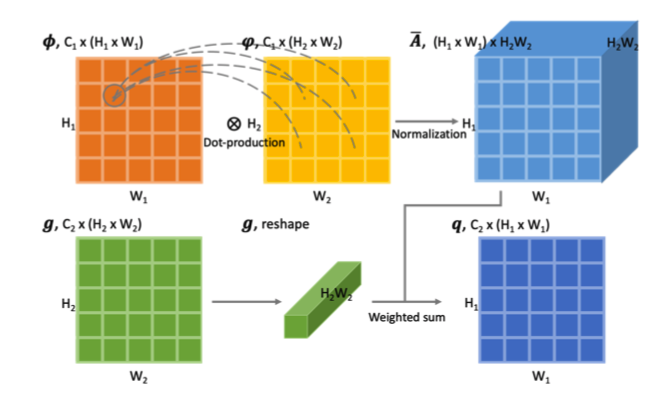
然后是 affinity module。AM通过两张图片的 embedded feature map,计算它们的 affinity,然后传递 supplementary messages。
Affinity 的计算:给定两个nodes、query function 和 key function,Affinity = query(image1) * key(image2)。这里的距离度量函数用的是点积(因为简单),其他的(高斯核函数、余弦距离)也可以。
Message passing: 计算出各个nodes间的affinity后,归一化,并以此为权重将所有有用的信息相加。
整个Affinity module的结果如下图所示:
上述的两张图片间的 affinity module 可以扩展到多张图片间,即 group affinity module(G-AM),以及一张图片内部的 self affinity module(S-AM)。
整体网络结构如下图所示:
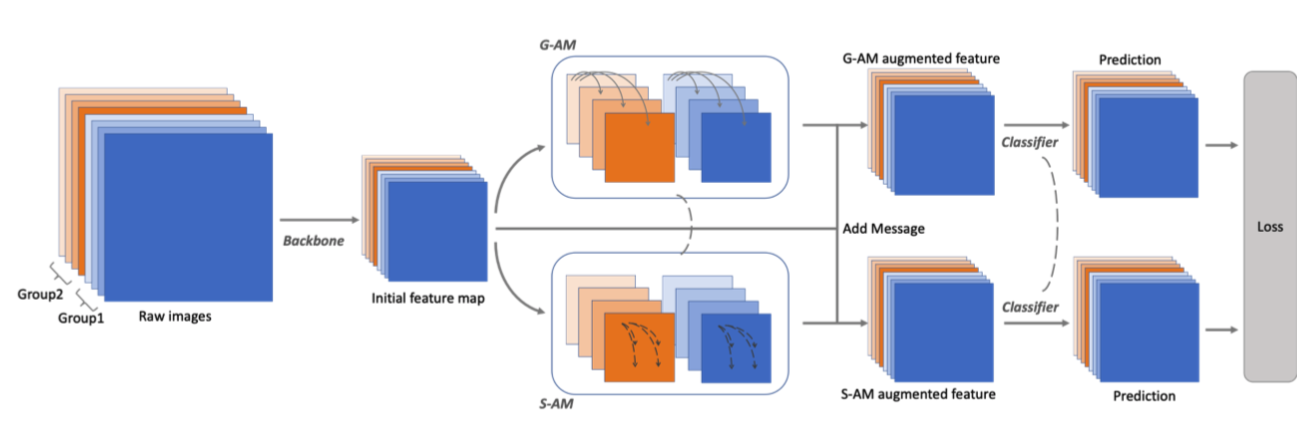
输入batch分为许多groups,每个group内部的图片至少有一个共同标签。通过backbone之后分为两支,G-AM和S-AM,分别根据 cross-image affinity 和 intra-image affinity 来计算出messages,以此增强原始feature,去预测分割结果。两支网络的参数全部共享。
Experiments
在Pascal VOC 2012 数据集上,他们达到了 64.1% mIOU (val) 和 64.7% mIOU(test) 的效果,超越了之前的state-of-the-art。
然后作者也做了许多 ablation study 来证明其方法的鲁棒性,具体可以参见文章。
我觉得比较有趣的是作者对affinity的可视化,可以更好地帮助我们理解同一个类别的图片间的相似性。

Conclusion
这篇文章主要通过挖掘图片间的关联度(cross-image relationship)来提高弱监督分割的效果,这个值得我们借鉴学习,可以考虑将其应用到其他的深度学习任务(classification... etc)上。