这是发表在 CVPR 2018 上的一篇关于弱监督目标定位的文章。
arxiv链接在https://arxiv.org/abs/1804.06962,作者的开源代码在 xiaomengyc/ACoL 。
Motivations
这篇文章提出了 Adversarial Complementary Learning (ACoL) 的方法在仅有图片标签的情况下完成目标定位的任务。
在CAM的文章中指出了最后一个卷积层得到的feature map可以得到各个类别的位置信息,但同时也存在一些问题:
- CAM过度依赖显著特征来对图片分类;
- 不能定位到整个目标物体(比如一只猫只能定位到头部)。
作者展现了一个新的网络框架,该框架使用了两支并行的分类器,其中一支动态地定位出一些显著的目标区域,然后通过擦除其中的某些区域并反馈给另一支分类器,能够让其发现新的目标区域,以此提升目标定位的效果。
ACoL有两个优点:
- 该模型可以端到端地训练;
- 动态擦除可以让第二支分类器更有效地发现新的目标区域。
在ILSVRC数据集上,该方法可以达到45.14%的Top-1的定位错误率。
Method
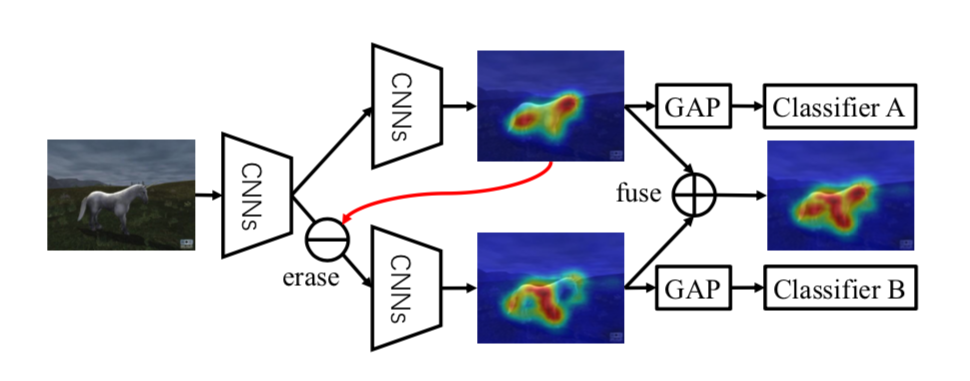
上图是对ACoL的一个解释。假设我们要定位一匹马,分类器A会发现一些显著区域(马的头和后腿),在分类器B的feature map中将这些部分擦除,可以让分类器B发现其他的显著区域(马的前腿),将这两部分融合起来,就能得到完整的目标区域(马)。
Revisiting CAM
原本的CAM需要在训练完VGG网络后,将其全连接层替换为GAP层再训练一次,作者提出了一种更方便得到CAM的方法。
图片通过FCN后得到feature map,在后面接两个3x3 的conv层和一个C-channel的1x1 conv层,然后通过GAP和softmax做分类。通过1x1 conv层后的feature map就是localization maps,与原始CAM是等价的。
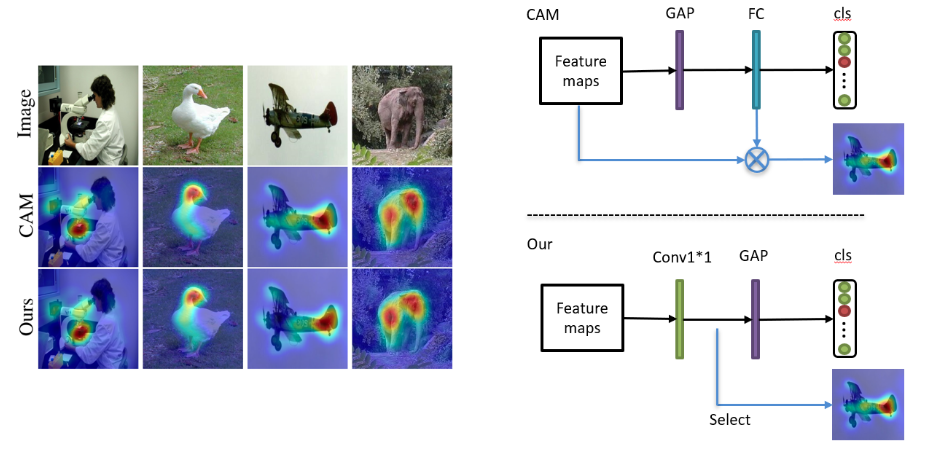
上图是作者提出的方法与原始CAM的结果对比以及模型对比。
The proposed ACoL
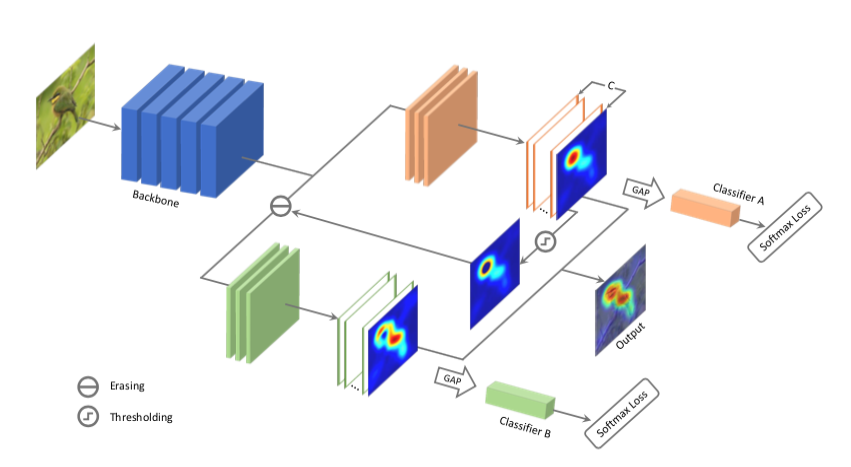
ACoL的整体框架如上图所示,包括三个部分:Backbone、分类器A和分类器B。
Backbone是一个全卷积网络(Fully Convolutional Network),用作特征提取器(feature extractor)。分类器A和分类器B都可以按照上述CAM的方式得到object localization maps,不过它们的输入不同,分类器B的输入是FCN的feature map减去分类器A的object localization maps中最显著区域后得到的部分。最终目标物体的localization maps由两支的结果融合后得到,融合方式是两支的结果取max。
算法流程如下所示:

Experiments
作者在ILSVRC、CUB-200-2011和Caltech-256三个数据集上进行了实验,使用VGG和GoogLeNet两种Backbone进行实验,主要与CAM进行对比,都能超越CAM的准确率,具体实验数据参见文章。
Ablation study是尝试不同的threshold对结果的影响,0.6或0.7可以达到最好的效果。
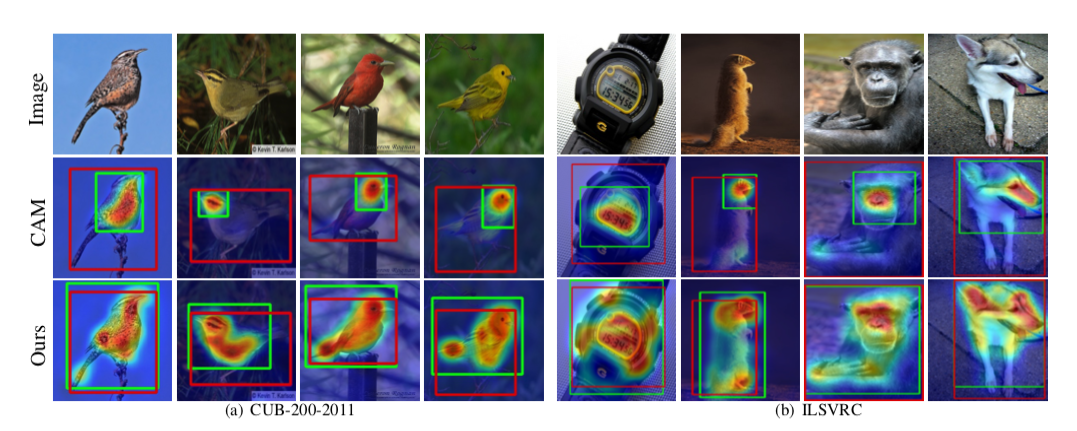
上图是ACoL与CAM在目标定位的结果对比示例,可以看到,ACoL更能捕捉到整个物体,这就是作者的出发点。
Conclusion
这篇文章的贡献点主要在两个方面:
- 提出了一个更简洁的得到CAM的方法;
- 通过擦除feature map上最显著的区域,让模型关注到其他区域,以此提高模型目标定位的效果。