这是发表在 ICCV 2015 上的一篇关于细粒度图像分类的文章。
作者的project链接在http://vis-www.cs.umass.edu/bcnn/,复现的开源代码在 HaoMood/bilinear-cnn ,pytorch版本,代码质量很高。
当前细粒度图像分类的state-of-the-art应该是CVPR 2018的文章:Learning a Discriminative Filter Bank within a CNN for Fine-grained Recognition,在CUB-200-2011鸟类数据集上使用VGG16 backbone能达到85.8%的准确率,而这片文章使用VGG16的backbone能达到84.1%的准确率,相差不算太大。
关于细粒度图像分类,业界大佬魏秀参在2017年写了一篇综述:「见微知著」——细粒度图像分析进展综述,
深度学习成功的一个重要精髓,就是将原本分散的处理过程,如特征提取、模型训练等,整合进了一个完整的系统,进行端到端的整体优化训练。
这篇文章提出的 Biliear-CNN,就是一个端到端的网络模型,能在CUB-200-2011数据集上,获得了当时弱监督细粒度分类的最好准确率。
Motivations
Bilinear model其实很早就提出了,之前的想法是对两种因素的变化进行建模(model two-factor variations),比如风格style和内容content(有点儿像style transfer)。另外blinear classifier之前也有人提出,将两个低秩矩阵的乘积作为classifier,这篇文章的外积想法也与之有关。
Method

上图就是这篇文章提出的网络模型。一个Bilinear模型 $ $ 由一个四元组组成:$ = (f_A, f_B, , ) \(,其中,\)f_A\(、\)f_B\(代表特征提取函数,即图中的CNN网络\)A\(和\)B\(,\)\(是一个池化函数,\)$是一个分类函数。
特征提取函数\(f(·)\)可以看作一个映射\(f: \mathcal{L}\times\mathcal{I}\to\mathcal{R}^{c \times D}\),将输入图像\(\mathcal{I}\)与位置区域\(\mathcal{L}\)映射为一个\(c\times D\)维的特征。得到的特征通过矩阵外积进行合并,得到最终的bilinear特征:\(bilinear(l,\mathcal{I},f_A,f_B) = f_A(l,\mathcal{I})^Tf_B(l,\mathcal{I})\)。
池化函数\(\mathcal{P}\)的作用是将所有位置的bilinear特征汇聚成一个特征,这篇文章中采用的池化方法是将所有位置的bilinear特征累加:\(\phi(\mathcal{I}) = \sum_{l\in \mathcal{L}}bilinear (l,\mathcal{I},f_A,f_B)\),这里得到的bilinear向量即可表示该细粒度图像。
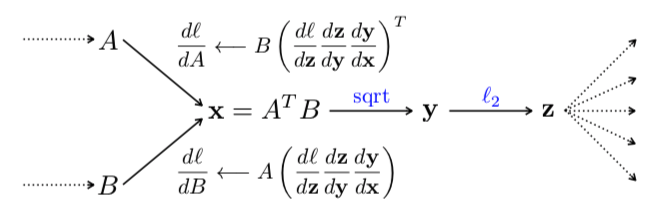
由于特征的位置维度被积分掉了,所以得到的bilinear特征向量是orderless的。另外,因为外积的原因,导致了特征的维度\(D\)增大为了原来的平方。
最后,将bilinear特征经过符号平方根运算,并经过\(l_2\)正则化,输入全连接分类器,完成分类任务。
为什么这两支网络会起作用?它们分别起什么样的作用?
作者在这篇文章中没有做深入的探讨,给了一种假说(hypothesis):网络A的作用是对物体/部件进行定位,而网络B则是用来对网络A检测到的物体位置进行特征提取。
Experiments
作者在CUB-200-2011、aircrafts和cars三个数据集上进行了实验,与FV-SIFT(Fisher vector representation with SIFT features)等方法进行了对比,具体实验数据参见下表。

下图展现的是fine-tune过的B-CNN模型的一些卷积核的相应情况,从这些图片可以看出,两支网络的作用并不是那么清晰可分的,这两支网络都会倾向于发现特定的语义部分(比如最后一行)。

Conclusion
Bilinear模型有着优异的泛化性能,不仅在细粒度图像分类上取得了优异的效果,还能被用于其他图像分类任务。